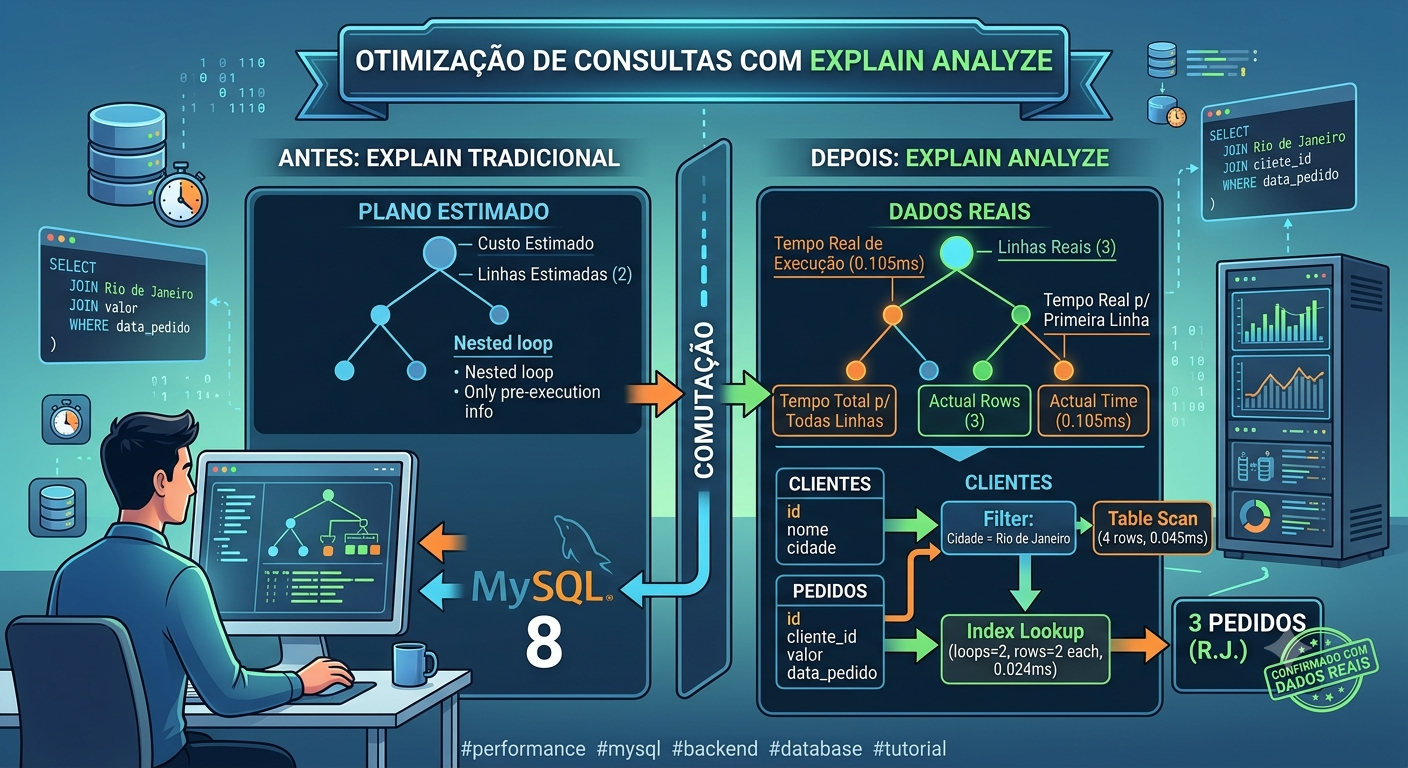
Quando escrevemos uma consulta SQL, o otimizador do MySQL cria um plano de execução. O EXPLAIN tradicional nos mostra esse plano com base em estatísticas que, às vezes, estão desatualizadas.
Já o EXPLAIN ANALYZE funciona como um “cronômetro de precisão”. Ele roda a consulta, monitora a execução em tempo real e descarta o resultado final, entregando um relatório detalhado de onde o banco de dados gastou mais energia.
Principais métricas retornadas Link para o cabeçalho
Ao analisar a saída, você encontrará três métricas principais para cada operação:
-
Actual time: O tempo real gasto para retornar a primeira linha e o tempo total para retornar todas as linhas (medido em milissegundos).
-
Actual rows: O número real de linhas que a operação processou.
-
Loops: Quantas vezes aquela operação específica foi repetida (comum em loops de Join).
Exemplo Prático: Estrutura e Dados Link para o cabeçalho
Para entender como ler essa saída, vamos criar um cenário clássico: uma tabela de clientes e uma tabela de pedidos.
1. Criando as Tabelas Link para o cabeçalho
CREATE TABLE clientes (
id INT AUTO_INCREMENT PRIMARY KEY,
nome VARCHAR(100) NOT NULL,
cidade VARCHAR(50)
);
CREATE TABLE pedidos (
id INT AUTO_INCREMENT PRIMARY KEY,
cliente_id INT,
valor DECIMAL(10, 2),
data_pedido DATE,
FOREIGN KEY (cliente_id) REFERENCES clientes(id)
);
2. Populando os Dados Link para o cabeçalho
Vamos inserir alguns registros simples para simular o ambiente:
INSERT INTO clientes (nome, cidade) VALUES
('Ana Silva', 'Rio de Janeiro'),
('Bruno Costa', 'São Paulo'),
('Carlos Souza', 'Rio de Janeiro'),
('Diego Santos', 'Belo Horizonte');
INSERT INTO pedidos (cliente_id, valor, data_pedido) VALUES
(1, 150.00, '2026-06-01'),
(1, 85.50, '2026-06-15'),
(2, 300.00, '2026-06-10'),
(3, 45.00, '2026-06-20');
Aplicando o EXPLAIN ANALYZE Link para o cabeçalho
Imagine que queremos buscar todos os pedidos feitos por clientes que moram no Rio de Janeiro. A nossa query seria:
SELECT p.id, p.valor, c.nome
FROM pedidos p
JOIN clientes c ON p.cliente_id = c.id
WHERE c.cidade = 'Rio de Janeiro';
Para analisar a execução real dessa consulta, basta prefixá-la com EXPLAIN ANALYZE:
EXPLAIN ANALYZE
SELECT p.id, p.valor, c.nome
FROM pedidos p
JOIN clientes c ON p.cliente_id = c.id
WHERE c.cidade = 'Rio de Janeiro';
Analisando o Resultado (Output) Link para o cabeçalho
A saída do MySQL será exibida em um formato de árvore textual (Tree Format). O resultado será parecido com este:
-> Nested loop inner join (cost=2.15 rows=2) (actual time=0.081..0.105 rows=3 loops=1)
-> Filter: (c.cidade = 'Rio de Janeiro') (cost=0.65 rows=2) (actual time=0.041..0.052 rows=2 loops=1)
-> Table scan on c (cost=0.65 rows=4) (actual time=0.034..0.045 rows=4 loops=1)
-> Index lookup on p using cliente_id (pedidos.cliente_id=c.id) (cost=0.63 rows=1) (actual time=0.021..0.024 rows=2 loops=2)
Como ler essa árvore? Link para o cabeçalho
A leitura deve ser feita de dentro para fora e de baixo para cima para acompanhar o fluxo dos dados.
-
Table scan on c(Linha 3): O MySQL começou fazendo uma varredura completa na tabela de clientes (c), lendo as 4 linhas existentes (rows=4). Isso levou cerca de0.045ms. -
Filter: (c.cidade = 'Rio de Janeiro')(Linha 2): Logo em seguida, ele aplicou o filtro da cidade. Das 4 linhas, restaram apenas 2 (rows=2). -
Index lookup on p using cliente_id...(Linha 4): Para cada um dos 2 clientes encontrados (loops=2), o MySQL usou o índice da chave estrangeira na tabela de pedidos (p) para buscar as linhas correspondentes. Ele encontrou um total de 3 pedidos no acumulado. -
Nested loop inner join(Linha 1): Por fim, juntou os dados e entregou as 3 linhas finais para o usuário. O tempo total da operação foi de0.105ms.
Conclusão Link para o cabeçalho
O EXPLAIN ANALYZE retira a “adivinhação” do processo de tunagem de consultas. Ao mostrar exatamente onde o tempo foi gasto e a quantidade real de dados movimentados, ele aponta com precisão cirúrgica se você precisa criar um novo índice, reescrever um Join ou mudar a estratégia de filtros da sua aplicação.